RunAnywhere: Ollama but for mobile, with a cloud fallback
Hey PH! Sanchit and Shubham (AWS/Microsoft) here 👋
Email: san@runanywhere.ai
Major update for local voice AI dropping soon, follow us on X – https://x.com/runanywhereai
Book a demo: https://calendly.com/sanchitmonga22/30min
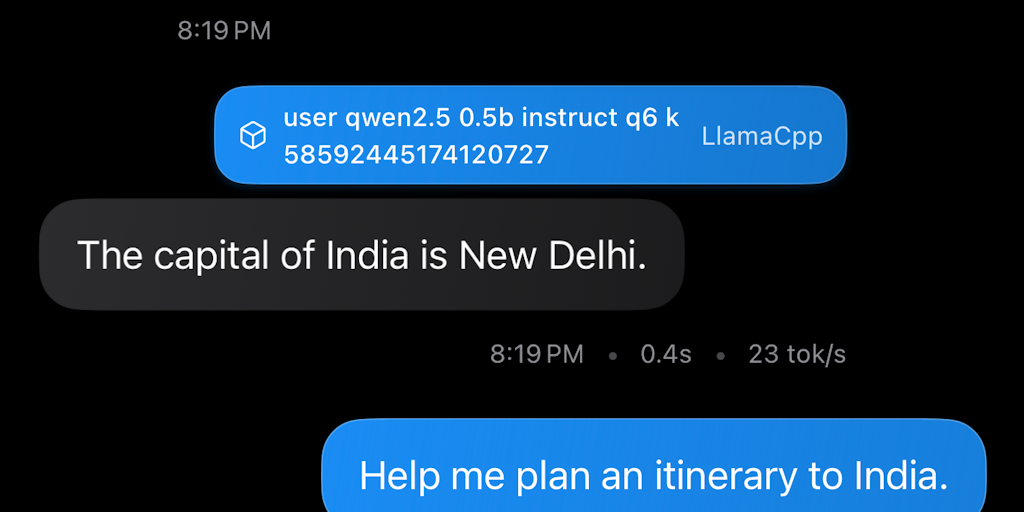
What it is: RunAnywhere is an SDK + control plane that makes on-device LLMs production-ready. One API runs models locally (GGUF/ONNX/CoreML/MLX) and a policy engine decides, per request, whether to stay on device or route to cloud.
Why it’s different:
– Native runtime (iOS + Android) with identical APIs
– Policy-based routing for privacy, cost, and performance
– No app update needed to swap models, prompts, or rules
– Analytics & A/B to see what actually works in the wild
Who should try it: Mobile teams building chat, copilots, summarization, PII-sensitive features, or anything that needs sub-200ms first-token and privacy by default.
How to test:
– Install the sample app (link on the PH page)
– Ping us for SDK access — we’ll help you wire it up in under an hour.
– Flip a policy and watch requests shift between device and cloud in real time
We’d love feedback on: your top on-device use case, target models/sizes, and must-have observability. Comments/DMs welcome — we’re here all day. 🚀